爬虫-怎么爬静态网站
爬虫-怎么爬静态网站
爬静态网站主要分为两部分:
爬静态网站的文字
爬静态网站的图片
[TOC]
爬文字
思路
用
requests模块得到网站的HTML用
BeautifulSoup模块得到HTML的正则文本用
find或者find_all函数从正则文本中得到自己想要的用
repalce去除不需要的字符
源代码
1 | # coding:utf-8 |
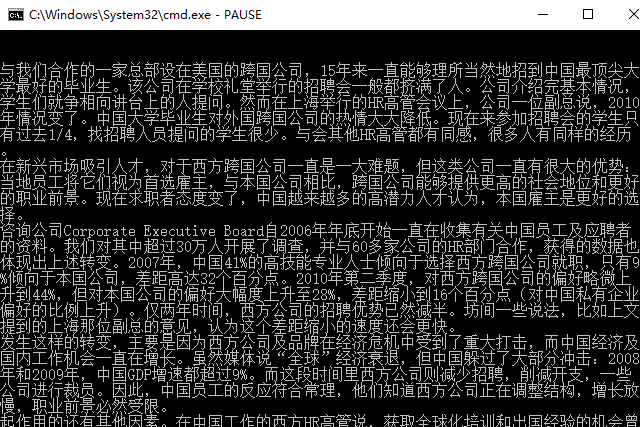
可以看到的结果
爬图片
思路
用requests模块得到网站的HTML
用BeautifulSoup得到HTML的正则文本
用find函数从正则文本中得到自己想要的,比如关键词img
利用urllib模块下载
利用for语句下载所有图片
源代码
1 | # coding:utf-8 |
爬虫时必须会用网页源代码
以爬图片为例:
这是我们要爬的网站:[https://darerd.github.io/2019/03/21/随想-新零售企业““智胜”未来/]
打开网站后(我用的Chrome浏览器),键盘快捷键F12,即可打开网站的调试模式,效果如下:
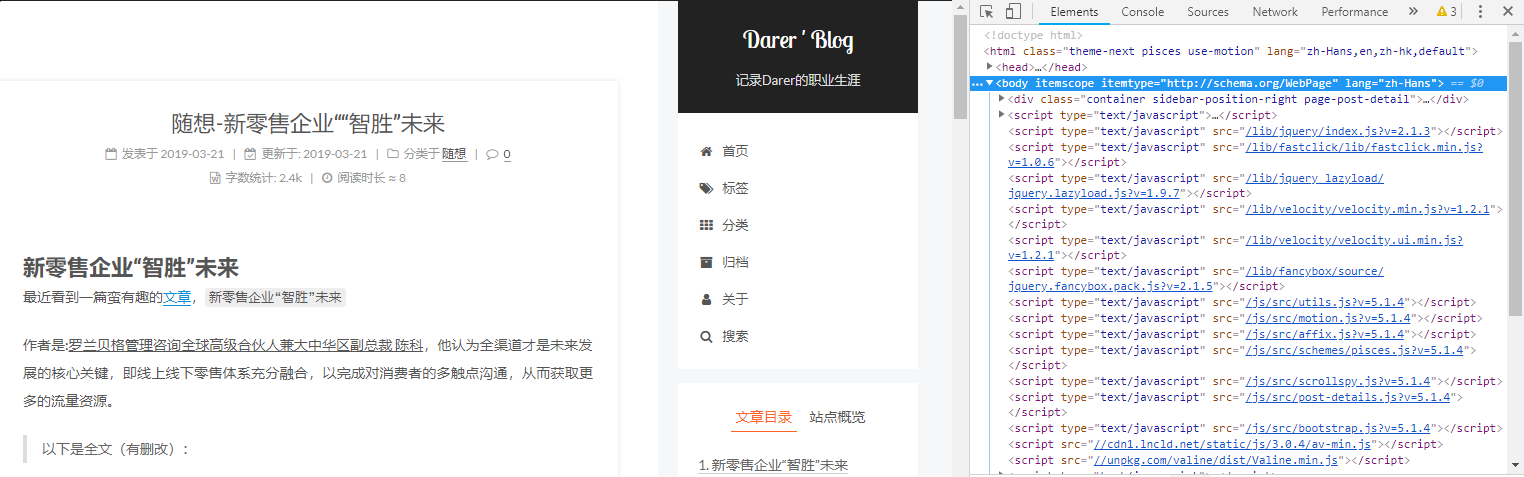
右侧就是网站的源代码,可以用来爬
如果需要快速定位到某一部分的代码所在位置,我们可以鼠标右键,选择检查,如下图所示:

如果我们要快速定位某图片所在的代码位置,演示如下:
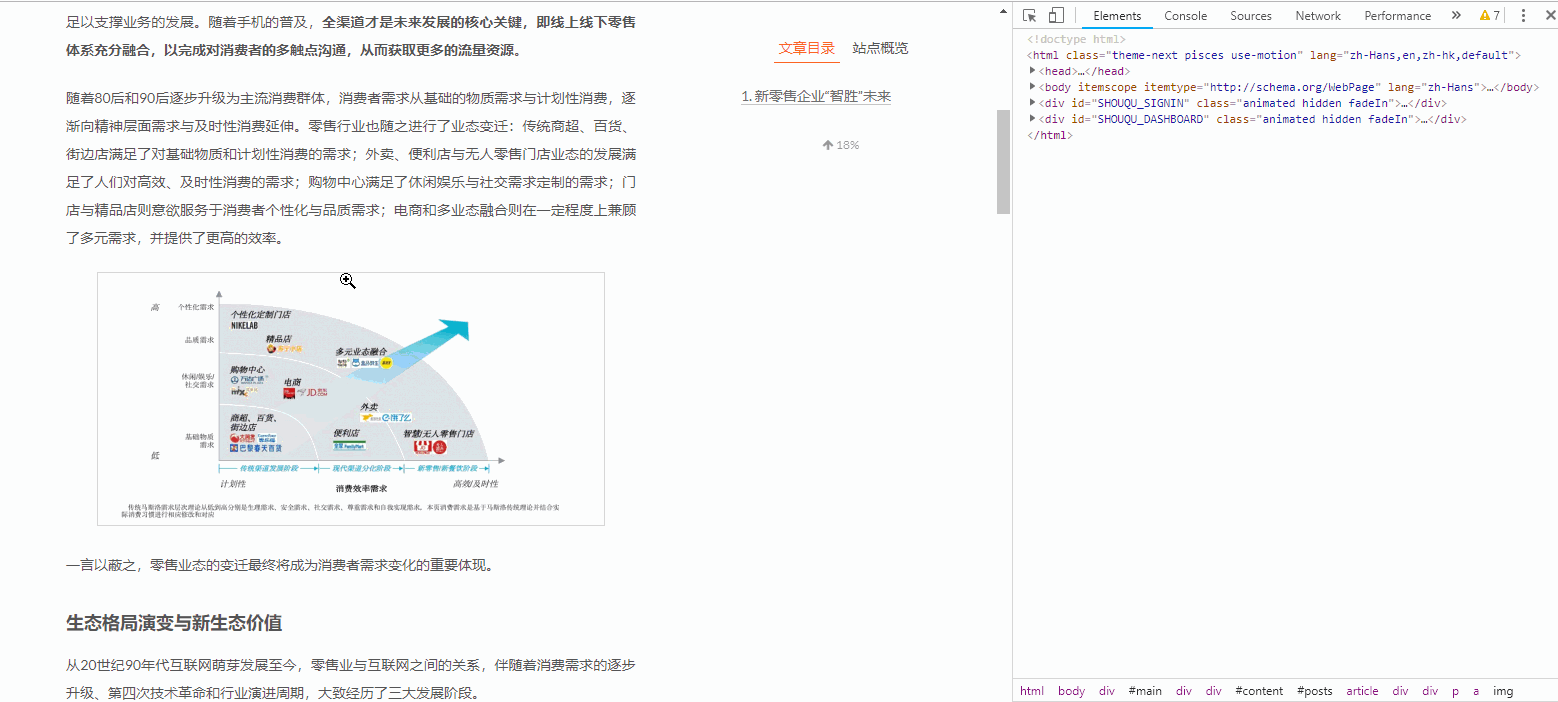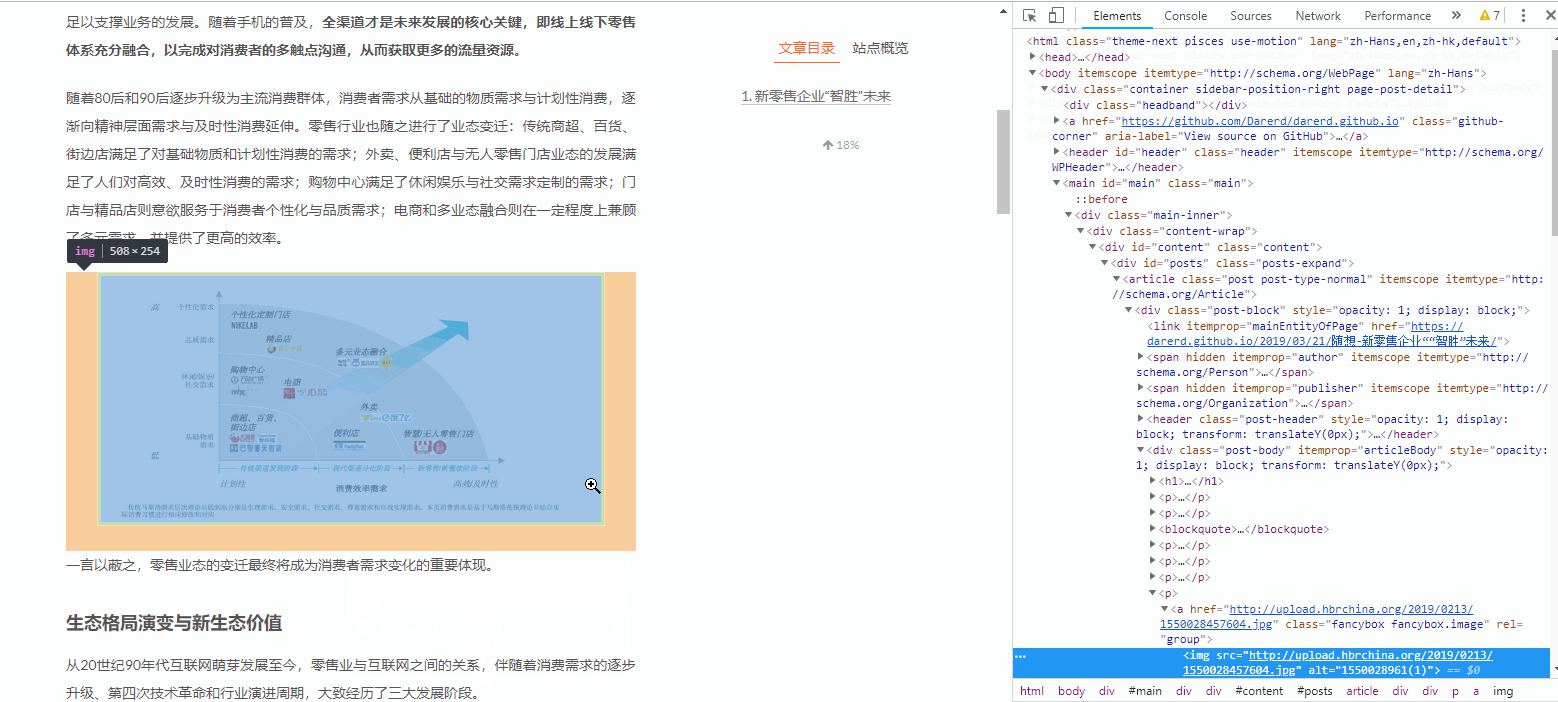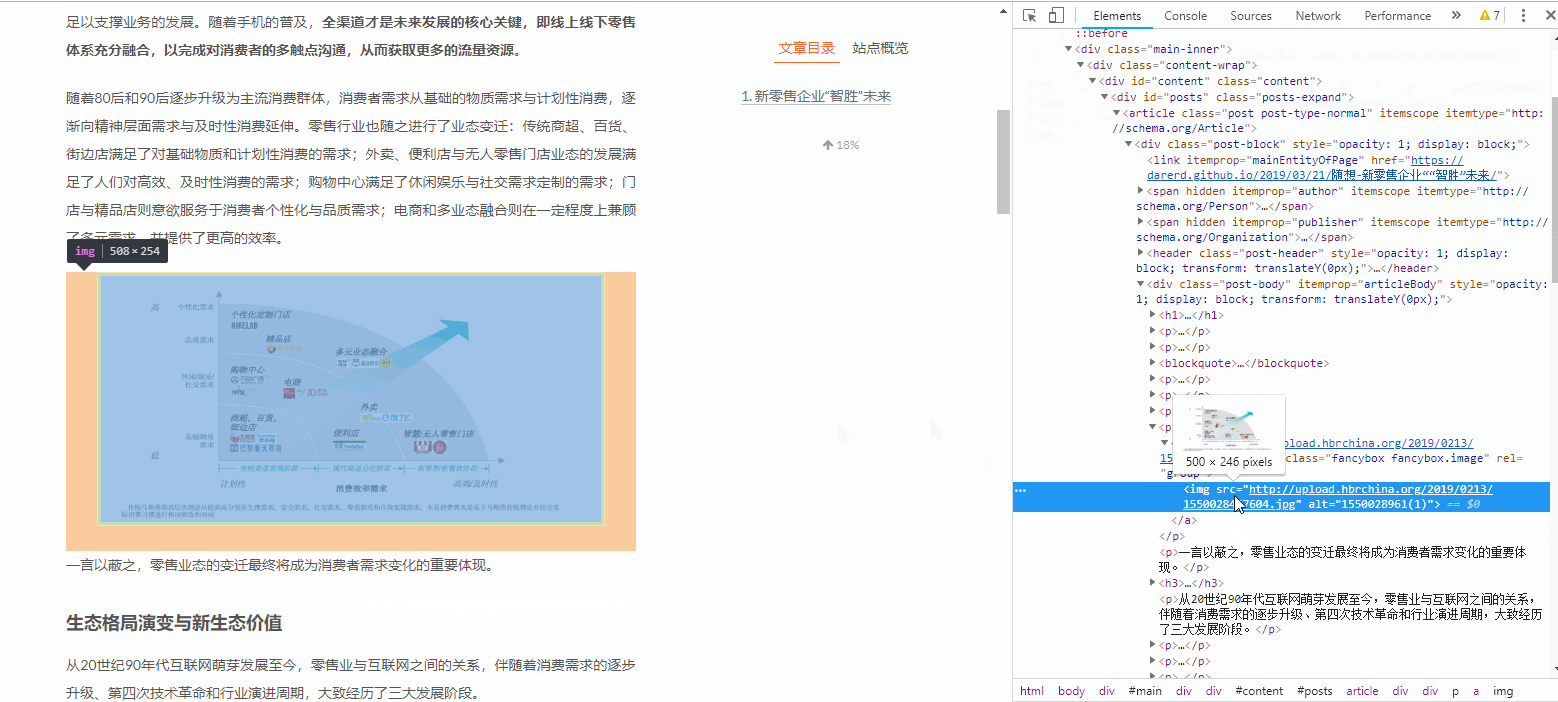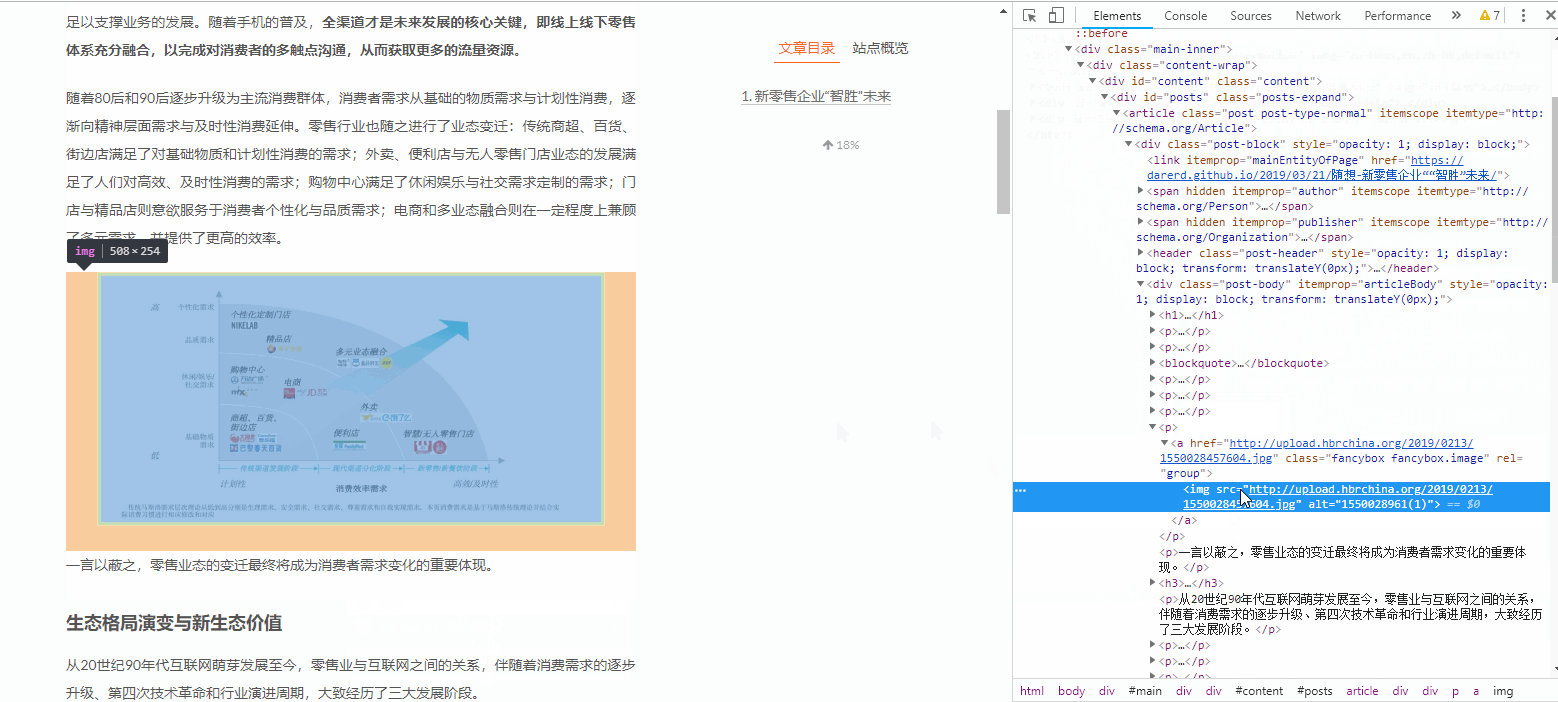
用这种方法观察每一张图片的源码:
它们的写法都是非常类似的,如下:
1 | <img |
src是图片的下载地址,alt是图片的便签,每一张图片都在img语句中
所以我们只要得到所有的img语句,然后从img语句中得到所有的src链接,就可以下载图片了。
每一种爬虫程序都类似,找到要爬部分的特点,然后调用相应的模块。
对于小白,难度就在于怎么样找到要爬部分的特点
以上
